Parameter sniffing in SQL Server is a feature where the query optimizer uses the specific parameter values passed to a stored procedure or query to generate an execution plan. While this can be beneficial for performance, it can also cause issues when the chosen execution plan is not optimal for other parameter values. This can lead to queries performing poorly for some inputs, particularly when the data distribution is uneven.
Why Parameter Sniffing Can Be a Problem
When SQL Server compiles a stored procedure or a parameterized query for the first time, it creates an execution plan based on the initial parameter values provided. If those initial values are atypical or represent edge cases, the generated plan might not perform well for more common parameter values.
How to Resolve Parameter Sniffing Issues
Use
OPTION (RECOMPILE)- Adding
OPTION (RECOMPILE)to a query forces SQL Server to generate a new execution plan every time the query is executed. - Pros: Ensures the plan is optimized for the specific parameter values at runtime.
- Cons: Recompiling the plan for every execution can add overhead, especially for frequently run queries.
SELECT * FROM Orders WHERE CustomerID = @CustomerID OPTION (RECOMPILE);- Adding
Use
WITH RECOMPILEin Stored Procedures- Adding
WITH RECOMPILEwhen creating or executing a stored procedure forces SQL Server to recompile the procedure each time it is executed. - Pros: Ensures the execution plan is tailored to the specific parameters each time.
- Cons: Similar to
OPTION (RECOMPILE), this can introduce overhead.
CREATE PROCEDURE GetOrders @CustomerID INT WITH RECOMPILE AS BEGIN SELECT * FROM Orders WHERE CustomerID = @CustomerID; END;- Adding
Optimize with
OPTION (OPTIMIZE FOR @parameter)- Use the
OPTIMIZE FORhint to instruct SQL Server to optimize the query for a specific parameter value, which might be more representative of typical use cases. - Pros: Can lead to a more consistent execution plan for typical cases.
- Cons: May still be suboptimal for other edge cases.
SELECT * FROM Orders WHERE CustomerID = @CustomerID OPTION (OPTIMIZE FOR (@CustomerID = 123));- Use the
Use
OPTIMIZE FOR UNKNOWN- This option tells SQL Server to generate a "generalized" execution plan rather than one based on the specific parameter values, as if the parameter values were not known at compile time.
- Pros: Useful when you want a more generic plan that doesn't overly favor any particular parameter value.
- Cons: The resulting plan might not be optimal for any specific case but can provide more stable performance across a range of values.
SELECT * FROM Orders WHERE CustomerID = @CustomerID OPTION (OPTIMIZE FOR UNKNOWN);Manually Create Multiple Plans with Different Parameters
- You can create separate stored procedures or queries optimized for different parameter ranges.
- Pros: Each version can be tailored to a specific type of query or set of parameter values.
- Cons: Increases maintenance complexity as you manage multiple versions of the same logic.
IF @CustomerID BETWEEN 1 AND 100 BEGIN EXEC GetOrders_SmallCustomers @CustomerID; END ELSE BEGIN EXEC GetOrders_LargeCustomers @CustomerID; END;Use Dynamic SQL
- Writing your query using dynamic SQL inside a stored procedure ensures the query plan is compiled fresh for each execution based on the actual parameter values.
- Pros: Tailors the execution plan to the exact values being passed.
- Cons: Dynamic SQL can make code harder to read and maintain and may have security implications (e.g., SQL injection risks).
DECLARE @SQL NVARCHAR(MAX); SET @SQL = 'SELECT * FROM Orders WHERE CustomerID = @CustomerID'; EXEC sp_executesql @SQL, N'@CustomerID INT', @CustomerID;Index Tuning
- Sometimes, parameter sniffing issues are exacerbated by suboptimal indexes. Reviewing and optimizing indexes can mitigate these issues.
- Pros: Can resolve the root cause by ensuring the most efficient data access methods.
- Cons: Requires analysis and might involve significant changes to the indexing strategy.
Monitoring and Diagnosing Parameter Sniffing
- Query Store: SQL Server's Query Store feature can help identify queries that suffer from parameter sniffing by tracking query performance and execution plans over time.
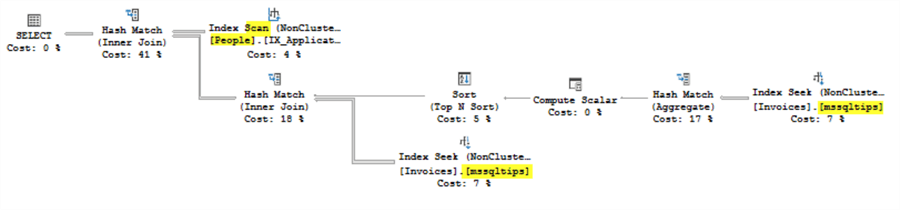
- Execution Plan Analysis: Comparing execution plans for different parameter values can reveal if parameter sniffing is causing suboptimal plans.
By applying these strategies, you can manage and mitigate the effects of parameter sniffing, leading to more consistent and reliable query performance in SQL Server.