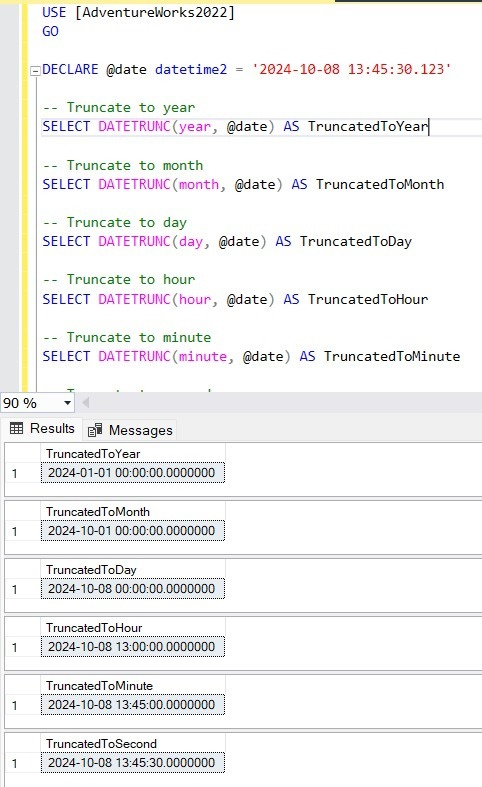
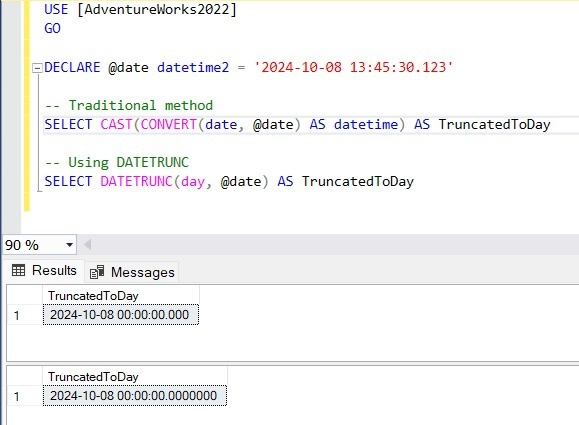
Cloud integration and hybrid data solutions involve combining on-premises infrastructure with cloud services to create flexible, scalable, and efficient data environments. This approach allows organizations to leverage the strengths of both local (on-premises) and cloud-based systems, enhancing performance, availability, and data management capabilities.
Here’s a deeper dive into Cloud Integration and Hybrid Data Solutions:
1. Hybrid Cloud Architecture
A hybrid cloud architecture combines private (on-premises) and public cloud environments. It allows data and applications to move between these environments, enabling:
- Flexibility: Workloads can be managed dynamically across on-premises and cloud environments based on performance, cost, or security needs.
- Cost Efficiency: You can keep sensitive or high-priority data on-premises while using the cloud for scalability and cost-effective storage.
- Disaster Recovery & High Availability: Data can be replicated or backed up in the cloud, ensuring business continuity in case of an on-premises failure.
2. Data Integration Strategies
Organizations can integrate data from multiple sources (on-premises, cloud databases, applications, IoT devices, etc.) to create a unified data platform. Key methods include:
- ETL/ELT: Extract, Transform, Load (ETL) or Extract, Load, Transform (ELT) pipelines move data between sources. ELT is more cloud-friendly as transformations occur after the data is loaded.
- Data Replication: Continuous replication of on-premises data to the cloud ensures data synchronization, providing low-latency access across environments.
- APIs: APIs connect various services, allowing applications in different environments to communicate seamlessly.
3. Cloud Data Services
Cloud platforms like Microsoft Azure, Amazon Web Services (AWS), and Google Cloud offer robust data solutions:
- Azure Synapse Analytics: Combines big data and data warehousing, offering real-time analytics over large datasets, whether stored on-premises or in the cloud.
- AWS Glue: Serverless data integration service that makes it easy to prepare data for analytics by combining data from various sources.
- Google BigQuery: Serverless data warehouse with built-in machine learning, designed for handling vast amounts of data across hybrid environments.
4. Multi-Cloud Strategy
Some organizations adopt a multi-cloud approach, using services from more than one cloud provider to avoid vendor lock-in, optimize costs, and improve redundancy. A well-executed multi-cloud strategy offers:
- Interoperability: Data and services work seamlessly across different cloud providers.
- Data Portability: Simplified movement of workloads between different cloud environments.
- Compliance & Regulation: Certain clouds may be chosen for specific workloads based on regional compliance or data residency requirements.
5. Edge Computing
Edge computing complements cloud and hybrid models by processing data closer to its source (e.g., IoT devices or local servers). This reduces latency and bandwidth costs, especially when processing time-sensitive data.
- Hybrid Edge Architecture: Combines edge computing with cloud services, sending processed data to the cloud for storage or further analysis while keeping latency-critical operations local.
- Use Cases: Real-time monitoring, predictive maintenance, and industrial automation.
6. Data Virtualization
Data virtualization allows for real-time access and query capabilities across diverse data sources without physically moving data. This reduces complexity in hybrid cloud scenarios, providing:
- Unified Data View: Access and manipulate data from multiple sources (cloud, on-premises, external) without duplication.
- Real-Time Analytics: Execute analytics directly on distributed datasets without the need for extensive ETL processes.
7. Security and Governance in Hybrid Solutions
Security remains a critical concern in hybrid solutions. Organizations need to implement:
- Data Encryption: Data must be encrypted both in transit (between environments) and at rest.
- Identity & Access Management (IAM): Ensure proper authentication and role-based access control (RBAC) for users across both cloud and on-premises environments.
- Compliance: Hybrid solutions need to meet regulatory standards (e.g., GDPR, HIPAA), especially when moving sensitive data between environments.
8. Cloud-Native Technologies in Hybrid Solutions
- Containers & Kubernetes: Kubernetes orchestrates containers across hybrid cloud environments, enabling portability and consistency in application deployment.
- Serverless Functions: Services like AWS Lambda, Azure Functions, and Google Cloud Functions allow code to run without provisioning servers, providing scalable compute in hybrid setups.
- Microservices Architecture: Enables the development of applications as small, independently deployable services. Microservices work well in hybrid environments, allowing specific services to run in the cloud while others remain on-premises.
9. Benefits of Hybrid Data Solutions
- Scalability: Utilize the cloud to handle spikes in demand while maintaining core workloads on-premises.
- Cost Control: Manage expenses by leveraging cloud resources dynamically and reducing dependency on expensive hardware.
- Innovation & Agility: Experiment with new cloud services (like machine learning, AI, or advanced analytics) without disrupting core on-premises operations.
- Data Sovereignty: Maintain control over sensitive data by keeping it on-premises while using the cloud for less critical data or compute-heavy tasks.
10. Real-World Use Cases
- Healthcare: Hybrid solutions allow sensitive patient data to remain on-premises while analytics and machine learning run in the cloud.
- Financial Services: Banks use hybrid architectures to comply with regulations that mandate data residency while leveraging cloud platforms for AI-driven risk assessment or fraud detection.
- Manufacturing: Edge devices collect data on the factory floor, process it locally, and send summary data to the cloud for further analysis.
By combining the strengths of on-premises systems and cloud platforms, cloud integration and hybrid data solutions offer businesses a path to scalable, secure, and cost-effective data management, enabling them to handle modern workloads and adapt to evolving technology landscapes.