Problem
Ask most T-SQL pros about their thoughts on WHILE loops or cursors, and you'll get a rant about the pitfalls and advice to avoid them. This advice is great, but hard to follow in practice when row-by-row operations plague your environment. When a DEV team creates an app, a WHILE loop might be their go-to solution if they come from a C# or C++ background. It's like the old saying that everything looks like a nail when your only tool is a hammer. WHILE loops work until they don't. Performance is painful when you start working with larger datasets, and the iterations keep growing. What can you do when your WHILE loop takes longer to process? Try your best to avoid them.
Solution
This article explores a few techniques to replace a pesky WHILE loop that was fast when it was new but slowed over time. I pieced most of these steps together from other articles on MSSQLTips.com. I'm not only a contributor but also a reader. While creating this solution, I went down a few dead ends only to learn what wouldn't work. In the end, some advice from a fellow author saved the day. After finishing this article, I hope you can use it to help solve a similar problem.
WHILE Loops
What exactly is a WHILE loop used for? In a WHILE loop, you set a condition and repeat an action until satisfying that condition. For example, you might declare a variable, set the value to a specific count based on the number of rows, and then perform a statement until all rows are processed. I've included a simple example below.
DECLARE @count INT = 10;
WHILE (@count > 0)
BEGIN
PRINT @count;
SET @count = @count - 1;
END;Results:
Developers often use WHILE loops when they insert data and need to retrieve new identity values of a table to perform another operation. Sometimes, you can work around this with the OUTPUT clause. In this article, Daniel Hutmacher outlines using the OUTPUT clause of a MERGE as a solution. I've suggested this method dozens of times. Another area where WHILE loops pop up is manipulating strings.
Secret Codes
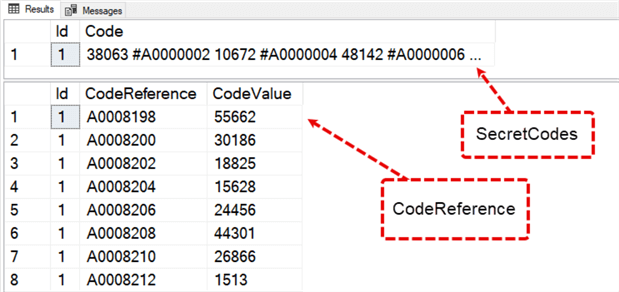
For a moment, imagine two tables. The first one is called SecretCodes (pictured below), and this table only contains two columns, an integer, and a huge string (VARCHAR(MAX)).
Inside the string column lives a sequence of numbers and codes separated by a single space. I've included an illustration below. The length of the code column ranges from 2,000 to 100,000 characters, hence the need for a VARCHAR(MAX) data type.
The image above highlights three strings that begin with #A, padded zeros, and finally, a number. This string is always nine characters long. The pattern varies for codes inserted between every integer, but it works for our example.
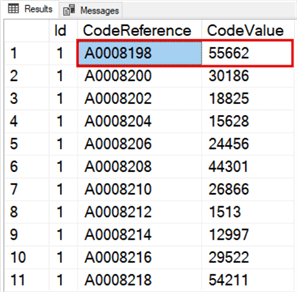
This code is where our second table comes into play. Our CodeReference table contains two columns: one is a list of codes (#A0000), and the other is the corresponding integer values. In the screenshot below, code #A0008198 (minus the # sign) has a value of 55662.
An important point to remember is that the CodeValue column changes every few days. Also, the business might decide to add new codes or delete existing ones.
In this example, we use the WHILE loop to update the SecretCode table and replace all the codes with their corresponding value from the CodeReference table. Let's put together a dataset and look at this in action.
Building Our Dataset
As mentioned previously, our end goal is to create two tables. The first holds the encrypted codes, and the other contains the actual referenced values. To reach our final destination, I'll first create a staging table.
USE [master];
GO
IF DATABASEPROPERTYEX('SecretCodeDemo', 'Version') IS NOT NULL
BEGIN
ALTER DATABASE SecretCodeDemo SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE SecretCodeDemo;
END;
GO
CREATE DATABASE SecretCodeDemo;
GO
ALTER DATABASE SecretCodeDemo SET RECOVERY SIMPLE;
GO
USE SecretCodeDemo;
GO
CREATE TABLE dbo.StageSecretCodes
(
Id INT NOT NULL,
RowNumber INT NOT NULL IDENTITY(1, 1),
Code NVARCHAR(MAX) NOT NULL,
CodeRef NVARCHAR(255) NULL,
OriginalCode INT NULL,
);
-- I want the numbers to be distinct.
WITH BaseData
AS (SELECT TOP 25000
ABS(CHECKSUM(NEWID()) % 60000) + 1 AS Code
FROM sys.all_columns AS n1
CROSS JOIN sys.all_columns AS n2),
BaseDataDistinct
AS (SELECT DISTINCT TOP 20000
Code
FROM BaseData)
INSERT INTO dbo.StageSecretCodes
(
Id,
Code,
OriginalCode
)
SELECT 1,
Code,
Code
FROM BaseDataDistinct;
UPDATE dbo.StageSecretCodes
SET CodeRef = CONCAT('#A', FORMAT(RowNumber, '0000000')),
Code = CONCAT('#A', FORMAT(RowNumber, '0000000'))
WHERE RowNumber % 2 = 0;
GOPopulating Our Tables
Since we created and populated the staging table with values, let's create the two main tables. We'll focus on them for the rest of the article.
CREATE TABLE dbo.CodeReference
(
Id INT NOT NULL,
CodeReference VARCHAR(250) NOT NULL,
CodeValue INT NOT NULL
);
INSERT INTO dbo.CodeReference
(
Id,
CodeReference,
CodeValue
)
SELECT Id,
REPLACE(CodeRef, '#', '') AS CodeReference,
OriginalCode
FROM dbo.StageSecretCodes
WHERE CodeRef IS NOT NULL;
CREATE TABLE dbo.SecretCodes
(
Id INT NOT NULL,
Code NVARCHAR(MAX) NOT NULL
);
CREATE NONCLUSTERED INDEX IX_CodeReference_CodeValue
ON dbo.CodeReference (
CodeReference,
CodeValue);
INSERT INTO dbo.SecretCodes
(
Id,
Code
)
SELECT Id,
STRING_AGG(CAST(Code AS VARCHAR(MAX)), ' ')
FROM dbo.StageSecretCodes
GROUP BY Id;
GO
CHECKPOINT;
SELECT *
FROM dbo.SecretCodes;
SELECT *
FROM dbo.CodeReference;
GOThe last two statements should return similar result sets, as seen in the screenshot below. Since we are generating random numbers, yours will be different.
Our CodeReference table contained less than 50 records in the past, yet now it holds over 10,000.
Creating a Backup
Before we proceed, let's execute the code below to create a copy_only backup. Update the file path to something that exists on your system, or you will get an error.
BACKUP DATABASE [SecretCodeDemo]
TO DISK = N'C:\code\MSSQLTips\SQLFiles\SecretCodeDemo.bak'
WITH COPY_ONLY,
NOFORMAT,
INIT,
NAME = N'SecretCodeDemo-Full Database Backup',
COMPRESSION,
STATS = 10;
GOThe WHILE Loop Version
I've included the code for the WHILE loop below. Running the process takes about two minutes on my system. With time and effort, you might optimize the code and improve performance. At one point, the CodeReference table and the number of codes were tiny, so everything seemed fine.
DECLARE @CodeLocator INT;
DECLARE @Code VARCHAR(25);
SELECT @CodeLocator = CHARINDEX('#', Code)
FROM dbo.SecretCodes;
SET NOCOUNT ON;
WHILE (@CodeLocator > 0)
BEGIN
SELECT @Code = SUBSTRING(Code, @CodeLocator, 9)
FROM dbo.SecretCodes;
UPDATE c
SET c.Code = REPLACE(c.Code, @Code, r.CodeValue)
FROM dbo.SecretCodes c
INNER JOIN dbo.CodeReference r
ON r.CodeReference = REPLACE(@Code, '#', '');
SELECT @CodeLocator = CHARINDEX('#', Code)
FROM dbo.SecretCodes;
END;
GOSQL performs 10,000 iterations for the code above before calling it quits for only one row in the SecretCodes table. What if there were dozens of rows? Let's find a better way.
Restore the Backup
Before we move on, let's run the code below to restore our database to work with the same dataset.
USE [master];
ALTER DATABASE [SecretCodeDemo]
SET SINGLE_USER
WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [SecretCodeDemo]
FROM DISK = N'C:\code\MSSQLTips\SQLFiles\SecretCodeDemo.bak'
WITH FILE = 1,
NOUNLOAD,
REPLACE,
STATS = 10;
ALTER DATABASE [SecretCodeDemo] SET MULTI_USER;
USE [SecretCodeDemo];
GOSplitting the String
The first step to move beyond a WHILE loop is splitting the single code string into separate rows. When each value and code is an individual row, we'll perform a set-based update statement and move past the iterative process. Now, onto a function with a lot of potential but fails in the end.
STRING_SPLIT
SQL Server 2016 introduced the STRING_SPLIT table-valued function, finally allowing a built-in method for splitting a string into rows. In the example below, the delimiter is a space.
SELECT value FROM STRING_SPLIT('Luke I am your father', ' ');Results:
value
---------------------
Luke
I
am
your
father
The STRING_SPLIT() function was the first method I tried. However, after testing and reading Aaron Bertrand's posts, I noticed a huge problem. Unless you're on SQL Server 2022 or an Azure flavor, there's no way to assign an order to the individual rows. I'm on SQL Server 2019. We need to put the strings back together in the same order they were initially. If they could be random, then STRING_SPLIT() might work. Let's not give up hope yet.
OPENJSON
The next table-valued function I tested was OPENJSON, which converts a JSON input into a relational format. Microsoft also introduced this function in SQL Server 2016. I borrowed the idea of splitting strings using OPENJSON from another article by Aaron.
SELECT seq = [Key],
Value
FROM OPENJSON(N'["' + REPLACE('Luke I am your father', ' ', N'","') + N'"]') AS x;Results:
seq value
------ ------
0 Luke
1 I
2 am
3 your
4 father
There you go, OPENJSON adds the order reference. Also, we need to wrap the OPENJSON inside another table-valued function for our purposes. The primary change I made to Aaron's original script was specifying a VARCHAR(MAX) for one of the input parameters. Run the code below to create the function before moving on.
CREATE OR ALTER FUNCTION dbo.SplitOrdered_JSON
(
@List NVARCHAR(MAX),
@Delimiter NCHAR(1)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(SELECT seq = [Key],
Value
FROM OPENJSON(N'["' + REPLACE(@List, @Delimiter, N'","') + N'"]') AS x);
GOPutting The String Back Together
Below is all the code I used to pull the string apart, update it, and reassemble it. The CTE names represent the actions taking place.
;WITH Split_Data
AS (SELECT s.Id,
CAST(sp.seq AS INT) AS seq,
sp.value
FROM dbo.SecretCodes s
CROSS APPLY dbo.SplitOrdered_JSON(s.Code, N' ') sp ),
Replace_Codes
AS (SELECT sd.Id,
CASE
WHEN c.CodeReference IS NULL THEN
sd.value
ELSE
c.CodeValue
END AS Code,
sd.seq
FROM Split_Data sd
LEFT JOIN dbo.CodeReference c
ON c.CodeReference = REPLACE(sd.value, '#', '')),
Reassemble_Data
AS (SELECT rc.Id,
STRING_AGG(CAST(rc.Code AS VARCHAR(MAX)), ' ')WITHIN GROUP(ORDER BY rc.seq) AS Code
FROM Replace_Codes rc
GROUP BY rc.Id)
UPDATE dbo.SecretCodes
SET dbo.SecretCodes.Code = cc.Code
FROM Reassemble_Data cc
INNER JOIN dbo.SecretCodes sc
ON sc.Id = cc.Id;
GO
SELECT *
FROM dbo.SecretCodes;
GOLet's look at each of the CTEs individually before the final update.
Split_Data
The first CTE uses the table-valued function dbo.SplitOrdered_JSON, which we created above, to split our string code into rows. Also, I'm casting the seq column as an integer because it's a character by default.
SELECT s.Id,
CAST(sp.seq AS INT) AS seq,
sp.value
FROM #SecretCodes s
CROSS APPLY dbo.SplitOrdered_JSON(s.Code, N' ') sp )Replace_Codes
The next one replaces the code (#A000) with its value from the CodeReference table. Note: The following two code blocks will fail if executed in isolation.
SELECT sd.Id,
CASE
WHEN c.CodeReference IS NULL THEN
sd.value
ELSE
c.CodeValue
END AS Code,
sd.seq
FROM Split_Data sd
LEFT JOIN #CodeReference c
ON c.CodeReference = REPLACE(sd.value, '#', '')Reassemble_Data
We are getting close to the finish line, and it's time to reassemble our string with the STRING_AGG function. This function concatenates the values of a string expression. Remember to add the WITHIN GROUP clause to order it.
SELECT rc.Id,
STRING_AGG(CAST(rc.Code AS VARCHAR(MAX)), ' ')WITHIN GROUP(ORDER BY rc.seq) AS Code
FROM ReplaceCodes rc
GROUP BY rc.IdOnce our string is in the proper format, we perform the UPDATE. The screenshot below illustrates the Code column after the statement completes.
Running the code above takes less than a second on my system. I marked this one as a win in my book.
Wrapping Up
The catalyst for me to write this article was the pain this problem caused, and in the end, the solution was easier than I thought. I'm glad experts like Aaron Bertrand and Jeff Moden took the time to test and write about these topics. If you can think of other ways to optimize the code above, please post it in the comments.
Key Points
- WHILE loops work until they don't. If you're confident your data set will stay small or is a one-time thing, then using them isn't much of a concern. I err on the side of tables growing unless they're fixed in depth and hold data like statuses or countries.
- As Aaron Bertrand wrote, it's a shame Microsoft doesn't expand the STRING_SPLIT ordering to versions of SQL Server pre-2022; at least 2019 or 2017 would make many people happy.
- The next time you review a pull request and see a WHILE loop, let the developer know your concerns. Often, code gets into the repo, and then a year later, someone else stumbles onto the script and reuses it, but now the data has grown.