Introduction
We all create a database, table, trigger, and Stored Procedure. Then we implement DML and DDL queries and fetch the desired result. Now the question is, was our task completed here?
The answer is no.
Because a bad logical database design results in a bad physical database design and generally results in poor database performance. So creation and implementation of data is one part of the task. After the creation of a database, improving performance is also important. A good database design provides the best performance during data manipulation which results in the best performance of an application. Users always want a fast response to their data retrieval action and developers put forth their best efforts to provide the data in the shortest time. Performance tuning is not easy and there aren't any Silver bullets, but we can go a surprisingly long way with a few basic guidelines.
Today we learn how to improve SQL Server Performance.
Select the Appropriate Data type
I think the selection of the data type for a column can have the most important role in database performance. If we select an appropriate data type then it will reduce the space and enhance the performance otherwise it generates the worst effect. So select an appropriate data type according to the requirements. SQL contains many data types that can store the same type of data but select an appropriate data type because each data type has some limitations and advantages over another data type.
The following are some guidelines about the selection of data type.
- Never use a nvarchar or nchar, instead use a varchar or char because nvarchar and nchar take a double amount of memory compared to varchar and char. Use nchar and nvarchar when we must store Unicode or 16-bit character data such as Hindi characters.
- Avoid the use of the text data type instead of varchar because the performance of varchar is much better than text. Use the text data type when we must store text data of more than 8000 characters.
Never use Select * Statement
When we require all the columns of a table then we usually use a “Select *” statement but this is not a good approach because when we use the “select *” statement then SQL Server convert * into all column names before executing the query and this approach takes some extra time and effort. So always provide all the column names in the query instead of “select *”.
Use Appropriate Naming Convention
The main goal of adopting a naming convention for database objects is so that you and others can easily identify the type and purpose of all objects contained in the database. A good naming convention decreases the time required in searching for an object. A good name clearly indicates the action name of any object that it will perform.
Select Appropriate choice between Exist and IN
I find that many programmers often suggest using Exist instead of IN but I am not satisfied with those people because it is not always correct that we use Exist instead of IN query. It mainly depends upon the amount of data. EXISTS provides the answer in the form of TRUE or FALSE & IN return values.
Now the question develops of which is faster, IN or EXISTS?
It totally depends upon the query. For some queries Exist is efficient and for some IN is efficient.
Exits is a correlated sub-query in which the outer query runs first and for each outer query, an inner query is probed.
Whereas in IN the sub-query is evaluated, distinct, indexed and then joined to the original table. So consider one big table (say 1 million rows) and one small table containing relatively fewer rows.
So if the outer table is small then it will be probed a fewer number of times and with the inner query (a big table) Exist will be faster.
If the inner query table (small table) is giving a smaller result set then IN will be faster. EXISTS will find the first row faster in general than the IN will and the IN will get the LAST row (all rows) faster then the where exists.
The recommendation at that time was
- If the majority of the filtering criteria are in the subquery, use IN.
- If the majority of the filtering criteria are in the main query, use EXISTS.
In other words
- IN for a large outer query and a small inner query.
- EXISTS for small outer query and big inner query.
Never use Count(*) or Count(1)
We should never use Count(*) or Count(1) in SQL. Instead of this, we should use Count (Col_Name).
Exception plan of Count(*), Count(1), Count (Col_Name) are the same.
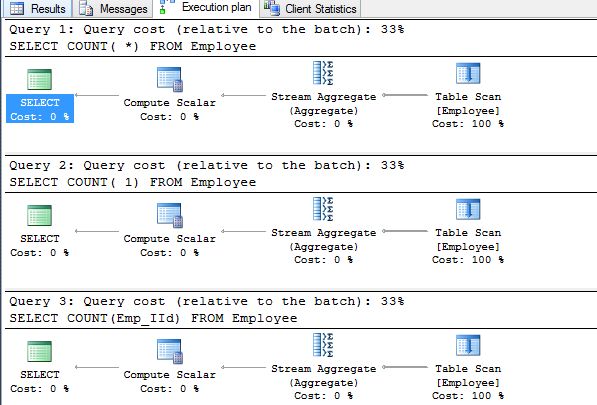
Then we should prefer Count (Col_name) because it provides a meaningful expression and the time taken may be slightly different in terms of CPU usage.
Never Use ” Sp_” for User Define Stored Procedure
Most programmers use “sp_” for user-defined Stored Procedures. I suggest never using “sp_” for user-defined Stored Procedures because, In SQL Server, the master database has a Stored Procedure with the "sp_" prefix, so when we create a Stored Procedure with the "sp_" prefix then SQL Server always looks first in the master database than in the user-defined database so it takes some extra time.
So we use another prefix for the user-defined Stored Procedure like “usp_” as in the following.
Avoid Cursors
A cursor is a temporary work area created in the system memory when a SQL statement is executed. A cursor is a set of rows together with a pointer that identifies a current row. It is a database object to retrieve data from a result set one row at a time. But the use of a cursor is not good because it takes a long time because it fetches data row by row.
So we can use a replacement of cursors. A Temporary table, For or While loop may be a replacement for a cursor in some cases.
Use Normalization
In creating a database, normalization is the process of organizing it into tables in such a way that the results of using the database are always unambiguous and as intended. It consists of decomposing tables to eliminate data redundancy and undesirable characteristics like insert, update and delete anomalies.
We should use the following 4 normalization rules in the creation of a database:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce & Codd Normal Form (BCNF)
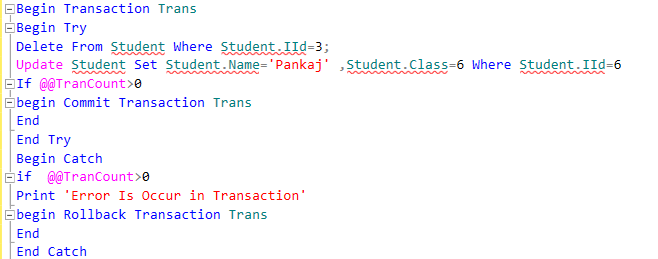
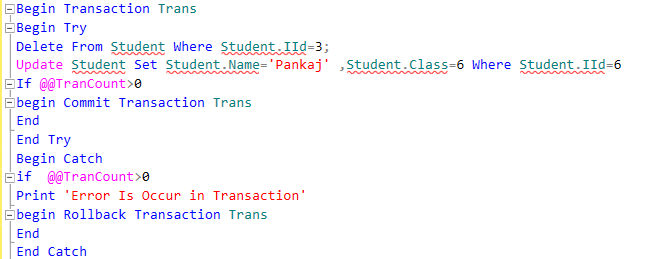
Use Try–Catch
In T-SQL a Try-Catch block is very important for exception handling. A best practice and use of a Try-Catch block in SQL can save our data from undesired changes. We can put all T-SQL statements in a TRY BLOCK and the code for exception handling can be put into a CATCH block.
Use Exception Handling for the following
- In Transaction Management for Rollback the transaction
- When using Cursor in SQL Server
- When implementing DML Query (Insert, Update, Delete) for checking errors and handling them.
Example
Avoid Multiple Joins
Try to avoid writing a SQL query using multiple joins that include outer joins, cross apply, and outer apply. It reduces the speed of execution and reduces the choices for the Optimizer to decide the join order and join type. We can use a temp table or temp variables instead of Multiple Joins.
Create and Use the Index
An index is a data structure to retrieve fast data. Indexes are special lookup tables that the database search engine can use to speed up data retrieval. Simply put, an index is a pointer to data in a table. Mainly an index increases the speed of data retrieval.
There are the following two types of indexes in SQL.
- Clustered Index- A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore a table can have only one clustered index and this is usually made on the primary key. The leaf nodes of a clustered index contain the data pages.
- Non-Clustered Index- A non-clustered index, on the other hand, does not alter the way the rows are stored in the table. It creates a completely different object within the table that contains the column(s) selected for indexing and a pointer back to the table's rows containing the data. A non-clustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on the disk.We should use the index in the table.
Use Primary Key
We should create a primary key on each table. It has two benefits. The first is that it uniquely identifies each record in the table and second it creates a clustered index that stores the data in the form of a B-Tree. So due to this approach, the retrieval of the data is very fast.
Column Level
Example
Table Level
Example
Use Alias Name
Aliasing renames a table or a column temporarily by giving another name. The use of table aliases means renaming a table in a specific SQL statement. Using aliasing, we can provide a small name to a large name which will save us time.
Use Stored Procedure
We should use a Stored Procedure for repeated data. Stored Procedures are compiled once and stored in executable form, so procedure calls are quick and efficient. Executable code is automatically cached and shared among users. The code for any repetitious database operation is the perfect candidate for encapsulation in procedures. This eliminates needless rewrites of the same code, decreases code inconsistency and allows the code to be accessed and executed by any user or application possessing the necessary permissions.

Find more about Stored Procedure here: Stored Procedure
Use Transaction Management
A transaction is a unit of work performed against the database. A transaction is a set of work (T-SQL statements) that execute together like a single unit in a specific logical order as a single unit. If all the statements are executed successfully then the transaction is complete and the transaction is committed and the data will be saved in the database permanently. If any single statement fails then the entire transaction will fail and then the complete transaction is either canceled or rolled back.
A transaction mainly contains 4 properties that are also known as ACID rules.
- Atomicity- Atomic means that all the work in the transaction is treated as a single unit.
- Consistency- Transaction ensures that the database properly changes states upon a successfully committed transaction.
- Isolation- It ensures that transactions operate independently and are transparent to each other.
- Durability- It ensures that the effect of a committed transaction will be saved in the database permanentlyand should persist no matter what (like due to power failure or something).
Conclusion
In the next article, we learned some other concepts to increase the performance of a SQL Server database.
No comments:
Post a Comment