Hello! Friends, this is my second article on this topic (Tips To Increase SQL Server Query Performance). Today we learn some new tips to increase the performance of SQL Server queries.
If you did not read the first part of this article series then I suggest you read that first.
- Tips to Increase SQL Server Query Performance: Part 1
If you already have read it then it is OK.
Let us begin this article.
Avoid Null value in the fixed length field
We should avoid the Null value in fixed-length fields because if we insert the NULL value in a fixed-length field then it will take the same amount of space as the desired input value for that field. So if we require a null value in a field then we should use a variable length field that takes less space for NULL. We should reduce the use of NULLS in the database. The use of NULLs in a database can reduce database performance, especially in WHERE clauses.
We should avoid the following data types
- CHAR- Fixed-length non-Unicode character data with a maximum length of 8,000 characters. (Use VARCHAR).
- NCHAR- Fixed-length Unicode data with a maximum length of 4,000 characters. (Use NVARCHAR).
- TEXT- Variable-length non-Unicode data with a maximum length of 2^31 - 1 (2,147,483,647) characters. (Use NTEXT).
- BINARY- Fixed-length binary data with a maximum length of 8,000 bytes. (Use VARBINARY).
Keep Clustered Index Small
We know that a clustered index is used for fast retrieval of data from tables. But I suggest that clustered Indexes should be Narrow, Unique, and Static.
First of all, we need to understand what Clustered Indexes are.
A Clustered Index is a special type of index that reorders the way records in the table are physically stored. Therefore the table can have only one Clustered Index and this is usually made on the Primary Key. The leaf nodes of a Clustered Index contain the data pages. It is like a dictionary, where all words are sorted in alphabetical order in the entire book. Since it alters the physical storage of the table, only one Clustered Index can be created per table.
Because a Clustered index stores data physically in memory, if the size of a clustered index is very large then it can reduce the performance. Hence a large clustered index on a table with a large number of rows increases the size significantly. Never use an index for frequently changed data because when any change in the table occurs then the index is also modified and that can degrade performance. Create an index on columns used in a WHERE clause and use it in aggregate operations, such as GROUP BY, DISTINCT, ORDER BY, MIN, MAX, and so on. We can create multiple indexes per table in SQL Server. Small or narrow indexes provide more options than a wide composite index.
Usually, Foreign Keys are used in joins, so an index created on Foreign Keys is always beneficial.
USE Common Table Expressions (CTEs) Instead of Temp table
We should prefer a CTE over the temp table because Temp tables are stored physically in a TempDB and they are permanent tables that are deleted after the session ends but CTEs are created within memory. Execution of a CTE is very fast compared to Temp Tables and it is very lightweight.
Use UNION ALL instead of UNION
I think we should use the UNION ALL instead of UNION because:
- UNION ALL doesn't sort the result set for distinguished values.
- UNION ALL is faster than UNION.
Use Schema Name
A schema is an organization or structure for a database. We can define a schema as a collection of database objects that are owned by a single principal and form a single namespace. Schema name helps the SQL Server for finding that object in a specific schema. It increases the speed of query execution.
We should use the schema name before the SQL object name followed by "." as in the following:
SET NOCOUNT ON
When an INSERT, UPDATE, DELETE, or SELECT command is executed then SQL Server returns the number affected by the query.
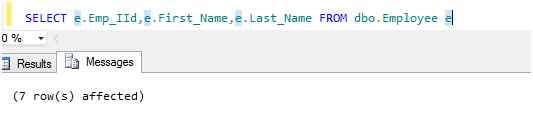
We can stop this by using NOCOUNT ON as in the following:
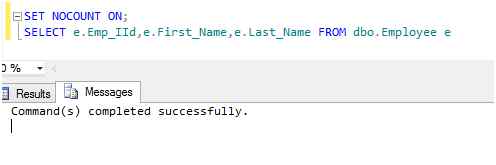
We can again unset the NONCOUNT using the “SET NONCOUNT OFF” command.
Remove Unused Index
Remove all unused indexes because indexes are always updated when the table is updated so the index must be maintained even if not used.
Use Relationship (Foreign Key) and Appropriate Action
A foreign key is a column or combination of columns that is the same as the primary key but in a different table. Foreign keys are used to define a relationship and enforce integrity between two tables. In addition to protecting the integrity of our data, FK constraints also help document the relationships between our tables within the database itself.
We should use the appropriate action for Delete and Update Operations.
SQL provides mainly 4 types of Action rules in maintaining relationships between tables for Delete and Update operations.
- No Action- If a value is deleted or updated from the parent table then no action (change) will be done on the child table.
- Set NULL- Associated values in a child table would be set to NULL if a value is deleted or updated from the parent table.
- Cascade- If a value is updated in the parent table then the associated values in the child table would also be updated and If the value is deleted from the parent table then the associated values in the child table would also be deleted.
Set Default
Associated values in a child table would be set to a default value specified in the column definition. Also, the default value should be present in the primary key column. Otherwise, the basic requirement of an FK relation would fail and the update/delete operation would not be successful. If no default value is provided in the foreign key column then this rule could not be implemented.
Use Index Name in Query
Although in most cases the query optimizer will pick the appropriate index for a specific table based on statistics, sometimes it is better to specify the index name in your SELECT query.
Select Limited Data
We should retrieve only the required data and ignore the unimportant data. The fewer data retrieved, the faster the query will run. Rather than filtering on the client, push as much filtering as possible on the server end. This will result in fewer data being sent on the wire and you will see results much faster.
Let us see an example in the following
In the preceding example, we can easily avoid the Emp_Iid from the query because we know that all Employees have a salary of 12000.
Drop Index before Insertion of Data
We should drop the index before the insertion of a large amount of data. This makes the insert statement run faster. Once the inserts are completed, you can recreate the index again.
Use Temp Table for Insertion of Large data
We can enhance our previous concept using a temp table. If you are inserting thousands of rows into a table, use a temporary table to load the data. You should ensure that this temporary table does not have an index. Since moving data from one table to another is much faster than loading from an external source, you can now drop indexes on your primary table, move data from the temporary to the final table and finally recreate the indexes.
Use Unique Constraint and Check Constraint
A Check constraint checks for a specific condition before inserting data into a table. If the data passes all the Check constraints then the data will be inserted into the table otherwise the data for insertion will be discarded. The CHECK constraint ensures that all values in a column satisfy certain conditions.
A Unique Constraint ensures that each row for a column must have a unique value. It is like a Primary key but it can accept only one null value. In a table, one or more columns can contain a Unique Constraint.
So we should use a Check Constraint and Unique Constraint because it maintains the integrity of the database.
Position of Column
If we are creating a Non-Clustered index on more than one column then we should consider the sequence of the columns. The order or position of a column in an index also plays a vital role in improving SQL query performance. An index can help to improve the SQL query performance if the criteria of the query match the columns that are left the most in the index key. So we should place the most selective column on the leftmost side of a non-clustered index.
Reduce the Number of Columns
We should reduce the number of columns in tables. That means that when more rows can fit on a single data page then that helps boost SQL Server read performance.
Recompiled Stored Procedure
We all know that Stored Procedures execute T-SQL statements in less time than a similar set of T-SQL statements executed individually. The reason is that the query execution plan for the Stored Procedures is already stored in the "sys.procedures" system-defined view.
We all know that recompilation of a Stored Procedure reduces SQL performance. But in some cases, it requires recompilation of the Stored Procedure.
These cases might be
- Dropping and altering of a column, index, and/or trigger of a table.
- Updating the statistics used by the execution plan of the Stored Procedure. Altering the procedure will cause the SQL Server to create a new execution plan.
We can recompile the Stored Procedure using one of the following two ways.
Recompile at the Creation of Stored Procedure
We can use the recompile option during the creation of the Stored Procedure like as.
But it has a big disadvantage in that it will always recompile every time we call the Stored Procedure so it can reduce the performance. We should avoid this method. We can refer to another method.
Recompile during Execution
In this method, we can create a Stored Procedure without a recompilation option. But we can use the recompilation option during the execution of the Stored Procedure. We should prefer this method for the recompilation of a Stored Procedure.
No comments:
Post a Comment